The landscape of AI competition is expanding. For years, the industry has focused on larger models, faster accelerators, and higher compute performance, but attention is increasingly shifting toward the infrastructure required to deploy AI reliably across real-world services and industrial environments. As AI adoption spreads across search, enterprise applications, content creation, manufacturing, data centers, and personal devices, the criteria for evaluating infrastructure are changing as well. AI infrastructure competitiveness is now determined not only by compute performance, but also by how efficiently data can be stored, moved, and reused.
AI infrastructure competition: From compute performance to data flows
By positioning HBM4,* HBM4E, SOCAMM2,* LPDDR,* and eSSDs as part of a connected AI memory portfolio, SK hynix is showing that infrastructure competition is moving beyond the performance of individual products and toward the design of the entire memory hierarchy. The key question is no longer only how fast a system can compute. It is also where data resides, how it is managed across different memory tiers, and how quickly it can be accessed when needed. [related article]
* LPDDR (Low Power Double Data Rate): A family of low-power DRAM products designed for energy-efficient operation in mobile devices. The LPDDR standard has evolved through multiple generations, including LPDDR1, LPDDR2, LPDDR3, LPDDR4, LPDDR4X, LPDDR5, LPDDR5X and LPDDR6.

Market predictions point in the same direction. Based on revenue forecasts from Gartner* and Omdia,* demand for HBM, AI-DRAM, and AI-NAND is expected to grow significantly in 2026 as AI infrastructure and on-device AI continue to expand. Gartner projects revenue growth of 92% for HBM and 60% for server DRAM, while Omdia forecasts a 130% increase in eSSD revenue. Rather than relying on a single memory technology, AI systems are increasingly built around multiple layers of memory and storage designed to support different workloads and deployment environments.
* Omdia: A market research and advisory firm within the Informa Group. Omdia is widely referenced across the semiconductor, display, data center, server and storage industries.
AI demand shifts from training to inference
Understanding this shift begins with the different demands that training and inference place on AI infrastructure. Training is the process of building AI models using large-scale datasets. At this stage, enormous computing power and high memory bandwidth are essential. Because training involves processing numerous parameters while repeatedly reading and writing data, memory capable of delivering large volumes of data close to the accelerator plays a critical role.
Inference, by contrast, is the stage at which a trained model responds to real-world user requests. Summarizing search results, generating documents, providing recommendations, and enabling AI systems to carry out tasks based on user instructions are all examples of inference. As AI services become more widely adopted, inference workloads are occurring more frequently, across a broader range of environments, and at ever-increasing scale.
While bandwidth and capacity remain the top priorities for training, inference places greater emphasis on responsiveness, power efficiency, data accessibility, and context retention. And as AI expands into real-time services and enterprise environments, simply running a model is no longer enough. Infrastructure must also retrieve relevant data quickly, preserve context across interactions, and connect outputs seamlessly to subsequent tasks. These capabilities are becoming increasingly important factors in determining overall infrastructure performance.

Larger context windows, more complex data flows
The evolution of AI services is closely tied to the growing volume of context data. The volume of data that AI systems draw on to generate more accurate responses and actions is growing rapidly, including user conversations, documents, search results, enterprise data, and application state information. Large language models (LLMs) capable of handling long-context workloads, as well as AI systems designed to execute multi-step tasks, do far more than process a single prompt. They must retain prior information, retrieve external data, and continuously feed that information back into the model workflow.
This makes data retrieval more important than ever. AI systems must locate relevant information across multiple layers of memory and storage, then use it throughout the inference process. Where data is stored, how quickly it can be accessed and how efficiently it moves between memory and storage all have a direct impact on overall system performance.
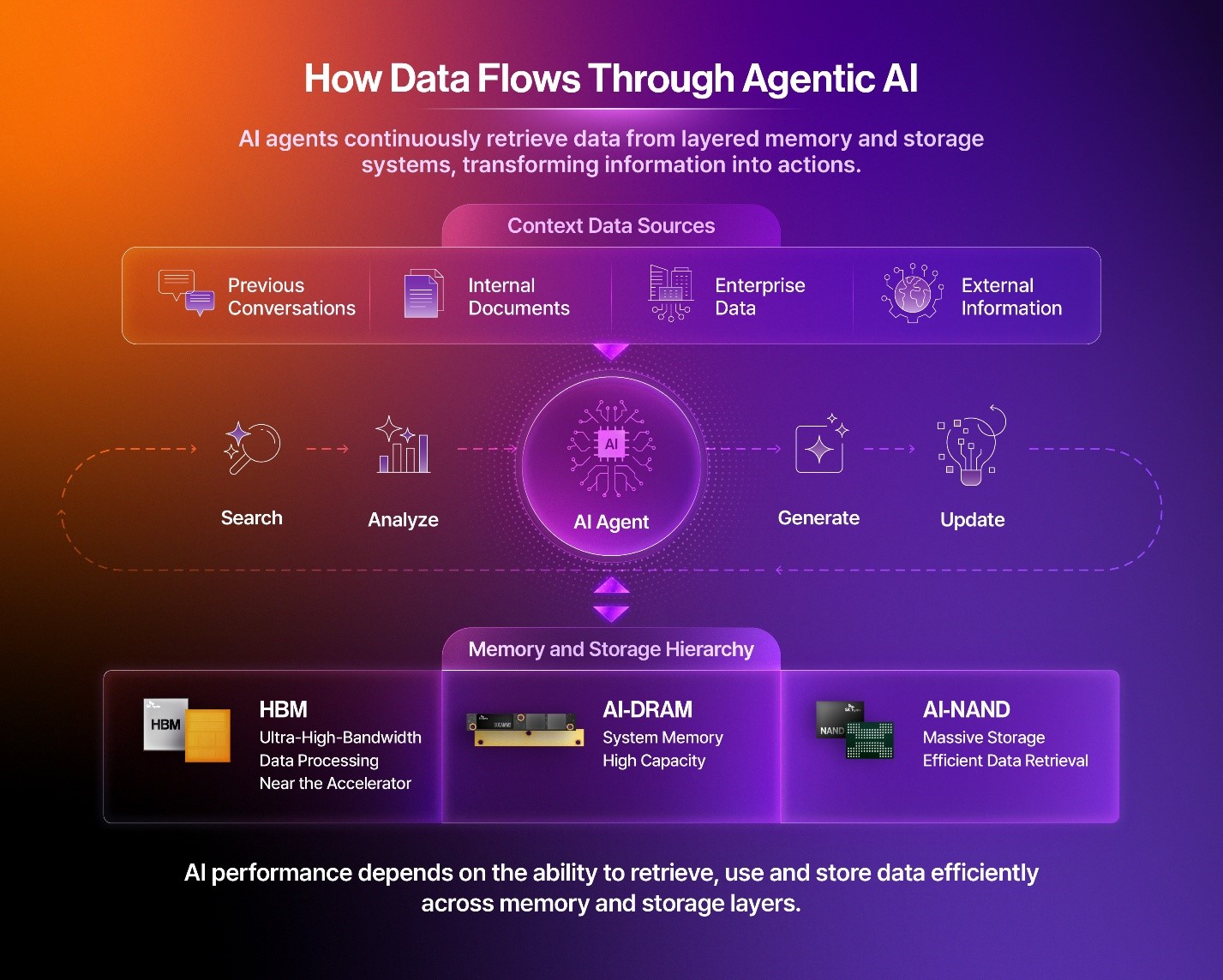
The rise of agentic AI* is making these data flows even more complex. Rather than simply answering a single question, agentic AI systems have to understand goals, plan multiple steps, and use the tools and data needed to complete a task. For example, when an AI agent is asked to prepare a report in an enterprise environment, it may need to search for internal documents, incorporate context from previous interactions, analyze relevant data, and then summarize the results. Rather than accessing data once and moving on, these workflows require data to be retrieved, updated, and reused repeatedly across multiple stages of execution.
These changes are elevating the role of system memory and storage alongside HBM in inference infrastructure. In particular, eSSDs capable of reliably storing large volumes of context data and model-related data while enabling fast retrieval are becoming increasingly important in enterprise AI* and data center environments. This trend is also reflected in SK hynix’s AI-NAND strategy, which centers on its 245TB QLC8 eSSD and next-generation high-performance storage technologies.
* QLC: NAND flash memory is classified based on the number of bits stored per cell (the smallest unit of storage): SLC (Single Level Cell, 1 bit), MLC (Multi Level Cell, 2 bits), TLC (Triple Level Cell, 3 bits), QLC (Quadruple Level Cell, 4 bits), and PLC (Penta Level Cell, 5 bits).
Memory layers optimized for different workloads
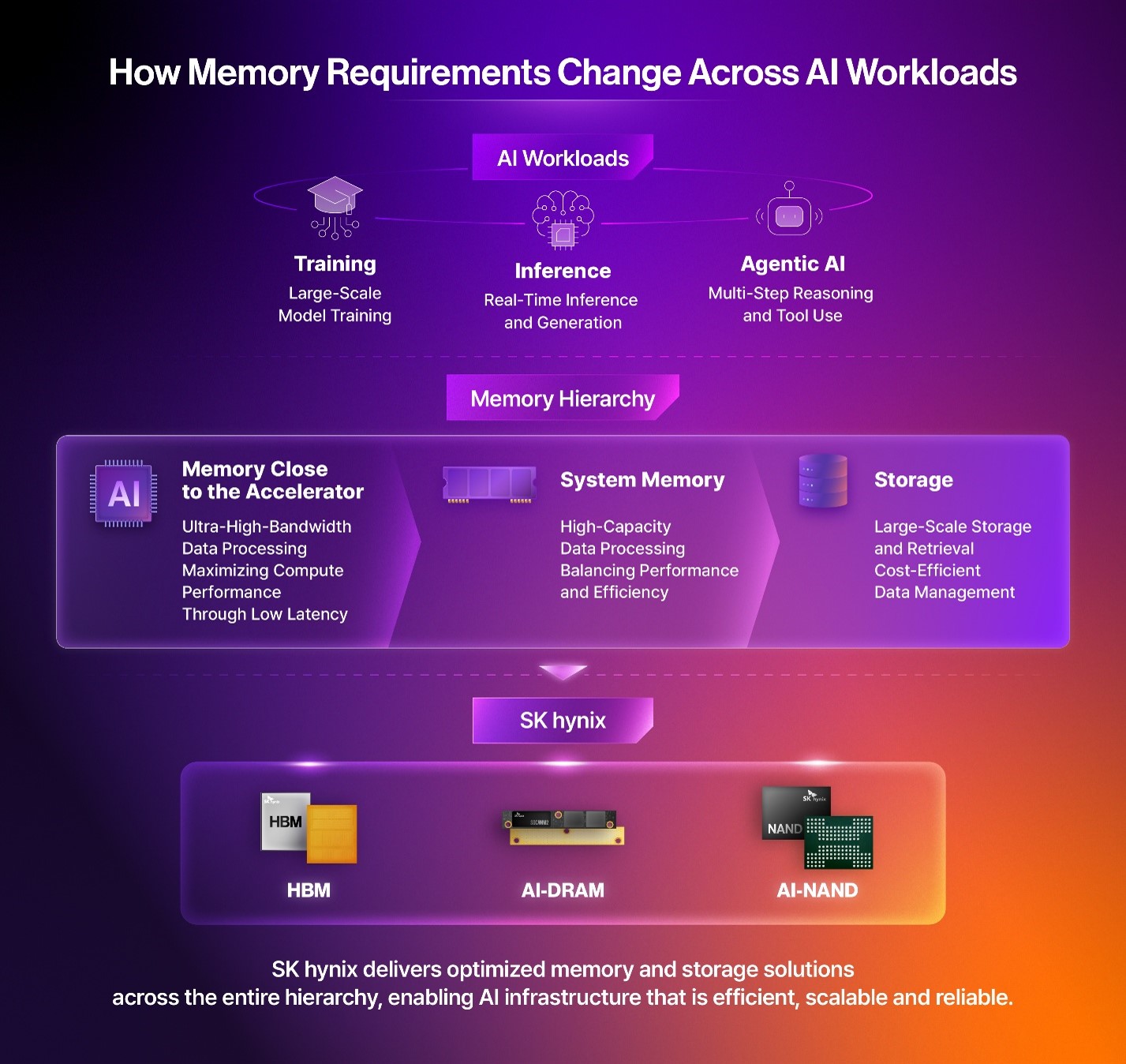
The shift toward memory-centric AI infrastructure also means that no single solution can meet the needs of every workload. Large-scale training requires high bandwidth and large memory capacity. High-performance inference depends on fast response times and efficient data processing. In AI PCs and on-device AI environments, power efficiency and form factors become critical considerations. In enterprise AI and data center environments, the ability to store massive volumes of data reliably and retrieve it quickly when needed is paramount.

HBM, AI-DRAM, and AI-NAND provide a useful framework for understanding how memory requirements vary across AI workloads. HBM helps reduce bandwidth bottlenecks close to the accelerator. AI-DRAM supports performance and efficiency across server and system memory environments. AI-NAND addresses growing storage and retrieval demands driven by inference workloads and data center operations. When these layers work together as part of a unified data flow, AI infrastructure can scale more efficiently and reliably.
The competitiveness of AI infrastructure depends on more than the performance of any single product. What matters is understanding the requirements of different workloads and determining how memory and storage should be deployed across the system. Compute-intensive workloads require high-bandwidth memory close to the processor, while the broader system depends on sufficient memory capacity and efficiency. Data-intensive workloads depend on high-performance storage. AI infrastructure operates most effectively when all these layers are connected as part of a single data flow.
Beyond products: SK hynix’s value in the AI infrastructure era
As AI infrastructure evolves into a layered memory architecture, SK hynix’s value to the industry extends beyond the performance of individual products because of its ability to design and optimize memory and storage hierarchies for different workloads.
This is what defines SK hynix’s position as a full-stack AI memory creator in the AI infrastructure era.
Building on its leadership in HBM, SK hynix is expanding its capabilities through a portfolio that supports the full memory hierarchy across a wide range of AI workloads while strengthening collaboration with customers. This broadens its role as both a memory provider for AI infrastructure and a global technology partner.
SK hynix continues to strengthen collaboration across the global AI ecosystem, deepening strategic partnerships with leading AI companies and customers to advance next-generation products and ensure a stable supply of high-performance memory. At the same time, the company is enhancing its understanding of computing systems and advancing technologies beyond HBM through its global research capabilities, enabling the company to respond more closely to the rapidly changing needs of AI infrastructure.
The next phase of AI will not be defined solely by larger models or faster accelerators. System competitiveness will depend on how efficiently data can be moved, stored, and reused. Furthermore, as AI infrastructure becomes more sophisticated, memory will play an even more important role as a foundational layer of system architecture.
SK hynix’s full-stack AI memory portfolio is aligned with this transition, positioning the company to enable the efficient deployment and scaling of AI systems in real-world environments.



